Edge AI
PeekingDuck supports running optimized TensorRT 1 models on devices with NVIDIA GPUs. Using the TensorRT model on these devices provides a speed boost over the regular TensorFlow/PyTorch version. A potential use case is running PeekingDuck on an NVIDIA Jetson device for Edge AI inference.
Currently, PeekingDuck includes TensorRT versions of the following models:
MoveNet model for pose estimation,
YOLOX model for object detection.
Installing TensorRT
The following packages are required to run PeekingDuck’s TensorRT models:
TensorFlow
PyTorch
PyCUDA
As the actual installation steps vary greatly depending on the user’s device, operating system, software environment, and pre-installed libraries/packages, we are unable to provide step-by-step installation instructions.
The user may refer to NVIDIA’s TensorRT Documentation for detailed TensorRT installation information.
Using TensorRT Models
To use the TensorRT version of a model, change the model_format of the model
configuration to tensorrt.
The following pipeline_config.yml shows how to use the MoveNet TensorRT model
for pose estimation:
1nodes:
2- input.visual:
3 source: https://storage.googleapis.com/peekingduck/videos/wave.mp4
4- model.movenet:
5 model_format: tensorrt
6 model_type: singlepose_lightning
7- draw.poses
8- dabble.fps
9- draw.legend:
10 show: ["fps"]
11- output.screen
The following pipeline_config.yml shows how to use the YOLOX TensorRT model
for object detection:
1nodes:
2- input.visual:
3 source: https://storage.googleapis.com/peekingduck/videos/cat_and_computer.mp4
4- model.yolox:
5 detect: ["cup", "cat", "laptop", "keyboard", "mouse"]
6 model_format: tensorrt
7 model_type: yolox-tiny
8- draw.bbox:
9 show_labels: True # configure draw.bbox to display object labels
10- dabble.fps
11- draw.legend:
12 show: ["fps"]
13- output.screen
Performance Speedup
The following charts show the speed up obtainable with the TensorRT models. The numbers were obtained from our in-house testing with the actual devices.
NVIDIA Jetson Xavier NX with 8GB RAM
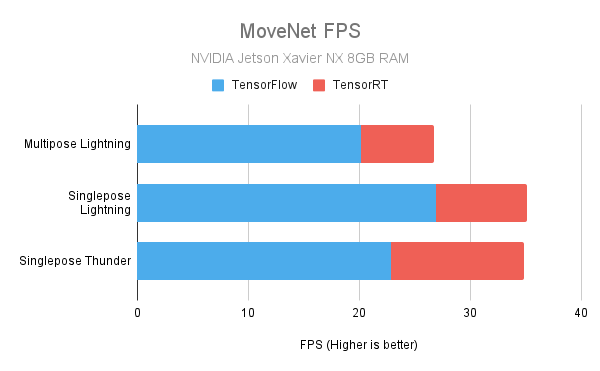
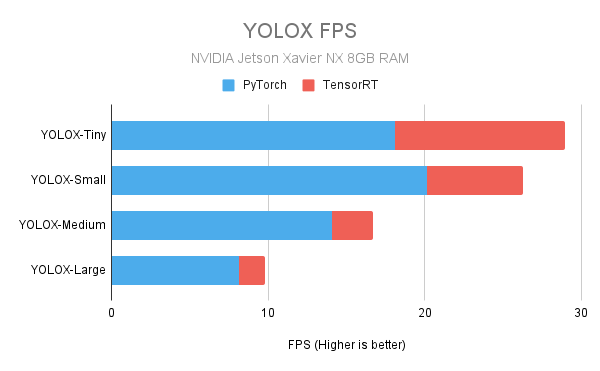
Jetson Xavier NX specs used for testing: 2
CPU: 6 cores (6MB L2 + 4MB L3)
GPU: 384-core Volta, 48 Tensor cores
RAM: 8 GB
NVIDIA Jetson Xavier AGX with 16GB RAM
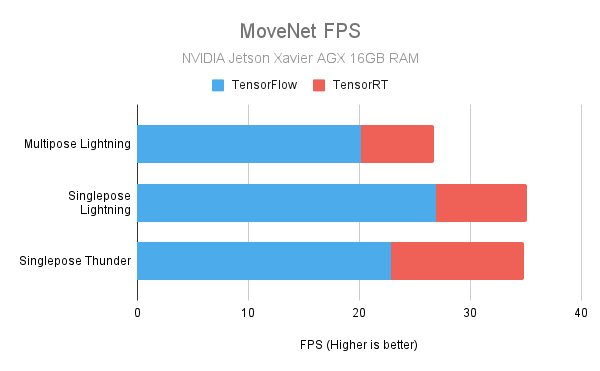
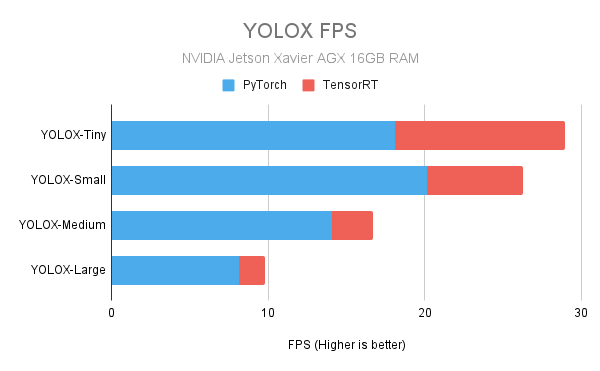
Jetson Xavier AGX specs used for testing: 3
CPU: 8 cores (8MB L2 + 4MB L3)
GPU: 512-core Volta, 64 Tensor cores
RAM: 16 GB
Test Conditions
- The following test conditions were followed:
- -
input.visual, the model of interest, anddabble.fpsnodes were used to perform inference on videos- 2 videos were used to benchmark each model, one with only 1 human (single), and the other with multiple humans (multiple)- Both videos are about 1 minute each, recorded at ~30 FPS, which translates to about 1,800 frames to process per video- 1280×720 (HD ready) resolution was used, as a bridge between 640×480 (VGA) of poorer quality webcams, and 1920×1080 (Full HD) of CCTVs- FPS numbers are averaged over 5 separate runs