Group Size Checking
Overview
As part of COVID-19 measures, the Singapore Government has set restrictions on the group sizes of social gatherings. AI Singapore has developed a vision-based group size checker that checks if the group size limit has been violated. This can be used in many places, such as in malls to ensure that visitors adhere to guidelines, or in workplaces to ensure employees’ safety.

To check if individuals belong to a group, we check if the physical distance between them is close. The most accurate way to measure distance is to use a 3D sensor with depth perception, such as a RGB-D camera or a LiDAR. However, most cameras such as CCTVs and IP cameras usually only produce 2D videos. We developed heuristics that are able to give an approximate measure of physical distance from 2D videos, addressing this limitation. This is further elaborated in the How It Works section.
Demo
To try our solution on your own computer, install and run PeekingDuck with the configuration file group_size_checking.yml as shown:
Terminal Session
How It Works
There are three main components to obtain the distance between individuals:
Human pose estimation using AI,
Depth and distance approximation, and
Linking individuals to groups.
1. Human Pose Estimation
We use an open source human pose estimation model known as PoseNet to identify key human skeletal points. This allows the application to identify where individuals are located within the video feed. The coordinates of the various skeletal points will then be used to determine the distance between individuals.

2. Depth and Distance Approximation
To measure the distance between individuals, we have to estimate the 3D world coordinates from the keypoints in 2D coordinates. To achieve this, we compute the depth \(Z\) from the x, y coordinates using the relationship below:
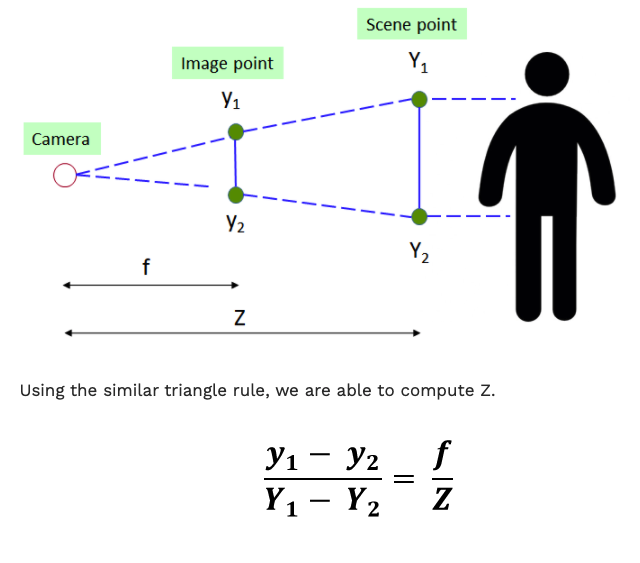
where:
\(Z\) = depth or distance of scene point from camera
\(f\) = focal length of camera
\(y\) = y position of image point
\(Y\) = y position of scene point
\(Y_1 - Y_2\) is a reference or “ground truth length” that is required to obtain the depth. After numerous experiments, it was decided that the optimal reference length would be the average height of a human torso (height from human hip to center of face). Width was not used as this value has high variance due to the different body angles of an individual while facing the camera.
3. Linking Individuals to Groups
Once we have the 3D world coordinates of the individuals in the video, we can compare the distances between each pair of individuals. If they are close to each other, we assign them to the same group. This is a dynamic connectivity problem and we use the quick find algorithm to solve it.
Nodes Used
These are the nodes used in the earlier demo (also in group_size_checking.yml):
nodes:
- input.visual:
source: 0
- model.posenet
- dabble.keypoints_to_3d_loc:
focal_length: 1.14
torso_factor: 0.9
- dabble.group_nearby_objs:
obj_dist_threshold: 1.5
- dabble.check_large_groups:
group_size_threshold: 2
- draw.poses
- draw.group_bbox_and_tag
- output.screen
1. Pose Estimation Model
By default, we are using the PoseNet model with a ResNet backbone for pose estimation. Please take a look at the benchmarks of pose estimation models that are included in PeekingDuck if you would like to use a different model or model type better suited to your use case.
2. Adjusting Nodes
Some common node behaviors that you might need to adjust are:
focal_length&torso_factor: We calibrated these settings using a Logitech c170 webcam, with 2 individuals of heights about 1.7m. We recommend running a few experiments on your setup and calibrate these accordingly.obj_dist_threshold: The maximum distance between 2 individuals, in meters, for them to be considered to be part of a group.group_size_threshold: The acceptable group size limit.
For more adjustable node behaviors not listed here, check out the API Documentation.
3. Using Object Detection (Optional)
It is possible to use object detection models instead of
pose estimation. To do so, replace the model node accordingly, and replace the node
dabble.keypoints_to_3d_loc with dabble.bbox_to_3d_loc. The reference or “ground truth
length” in this case would be the average height of a human, multiplied by a small factor.
You might need to use this approach if running on a resource-limited device such as a Raspberry Pi. In this situation, you’ll need to use the lightweight models; we find lightweight object detectors are generally better than lightweight pose estimation models in detecting humans.
The trade-off here is that the estimated distance between individuals will be less accurate. This is because for object detectors, the bounding box will be compared with the average height of a human, but the bounding box height decreases if the person is sitting down or bending over.