PeekingDuck offers pre-trained model nodes that can be used to tackle a wide variety of
problems, but you may need to train your own model on a custom dataset sometimes. This tutorial
will show you how to package your model into a custom model node, and use it with
PeekingDuck. We will be tackling a manufacturing use case here - classifying images of steel
castings into “defective” or “normal” classes.
Casting is a manufacturing process in which a material such as metal in liquid form is poured into
a mold and allowed to solidify. The solidified result is also called a casting. Sometimes,
defective castings are produced, and quality assurance departments are responsible for preventing
defective pieces from being used downstream. As inspections are usually done manually, this adds
a significant amount of time and cost, and thus there is an incentive to automate this process.
The images of castings used in this tutorial are the front faces of steel pump impellers. From the comparison below, it can be seen that the
defective casting has a rough, uneven edges while the normal casting has smooth edges.
PeekingDuck is designed for model inference rather than model training. This optional section
shows how a simple Convolutional Neural Network (CNN) model can be trained separately from the
PeekingDuck framework. If you have already trained your own model, the
following section describes how you can
convert it to a custom model node, and use it within PeekingDuck for inference.
Create an empty train_classifier.py file within the castings_project folder, and update it
with the following code:
train_classifier.py:
Show/Hide Code for train_classifier.py
1""" 2Script to train a classification model on images, save the model, and plot the training results 3 4Adapted from: https://www.tensorflow.org/tutorials/images/classification 5""" 6 7importpathlib 8fromtypingimportList,Tuple 9 10importmatplotlib.pyplotasplt 11importtensorflowastf 12fromtensorflow.kerasimportlayers 13fromtensorflow.keras.modelsimportSequential 14fromtensorflow.keras.layers.experimental.preprocessingimportRescaling 15 16# setup global constants 17DATA_DIR="./castings_data" 18WEIGHTS_DIR="./weights" 19RESULTS="training_results.png" 20EPOCHS=10 21BATCH_SIZE=32 22IMG_HEIGHT=180 23IMG_WIDTH=180 24 25 26defprepare_data()->Tuple[tf.data.Dataset,tf.data.Dataset,List[str]]: 27""" 28 Generate training and validation datasets from a folder of images. 29 30 Returns: 31 train_ds (tf.data.Dataset): Training dataset. 32 val_ds (tf.data.Dataset): Validation dataset. 33 class_names (List[str]): Names of all classes to be classified. 34 """ 35 36train_dir=pathlib.Path(DATA_DIR,"train") 37validation_dir=pathlib.Path(DATA_DIR,"validation") 38 39train_ds=tf.keras.preprocessing.image_dataset_from_directory( 40train_dir, 41image_size=(IMG_HEIGHT,IMG_WIDTH), 42batch_size=BATCH_SIZE, 43) 44 45val_ds=tf.keras.preprocessing.image_dataset_from_directory( 46validation_dir, 47image_size=(IMG_HEIGHT,IMG_WIDTH), 48batch_size=BATCH_SIZE, 49) 50 51class_names=train_ds.class_names 52 53returntrain_ds,val_ds,class_names 54 55 56deftrain_and_save_model( 57train_ds:tf.data.Dataset,val_ds:tf.data.Dataset,class_names:List[str] 58)->tf.keras.callbacks.History: 59""" 60 Train and save a classification model on the provided data. 61 62 Args: 63 train_ds (tf.data.Dataset): Training dataset. 64 val_ds (tf.data.Dataset): Validation dataset. 65 class_names (List[str]): Names of all classes to be classified. 66 67 Returns: 68 history (tf.keras.callbacks.History): A History object containing recorded events from 69 model training. 70 """ 71 72num_classes=len(class_names) 73 74model=Sequential( 75[ 76Rescaling(1.0/255,input_shape=(IMG_HEIGHT,IMG_WIDTH,3)), 77layers.Conv2D(16,3,padding="same",activation="relu"), 78layers.MaxPooling2D(), 79layers.Conv2D(32,3,padding="same",activation="relu"), 80layers.MaxPooling2D(), 81layers.Conv2D(64,3,padding="same",activation="relu"), 82layers.MaxPooling2D(), 83layers.Dropout(0.2), 84layers.Flatten(), 85layers.Dense(128,activation="relu"), 86layers.Dense(num_classes), 87] 88) 89 90model.compile( 91optimizer="adam", 92loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), 93metrics=["accuracy"], 94) 95 96print(model.summary()) 97history=model.fit(train_ds,validation_data=val_ds,epochs=EPOCHS) 98model.save(WEIGHTS_DIR) 99100returnhistory101102103defplot_training_results(history:tf.keras.callbacks.History)->None:104"""105 Plot training and validation accuracy and loss curves, and save the plot.106107 Args:108 history (tf.keras.callbacks.History): A History object containing recorded events from109 model training.110 """111acc=history.history["accuracy"]112val_acc=history.history["val_accuracy"]113loss=history.history["loss"]114val_loss=history.history["val_loss"]115epochs_range=range(EPOCHS)116117plt.figure(figsize=(16,8))118plt.subplot(1,2,1)119plt.plot(epochs_range,acc,label="Training Accuracy")120plt.plot(epochs_range,val_acc,label="Validation Accuracy")121plt.legend(loc="lower right")122plt.title("Training and Validation Accuracy")123124plt.subplot(1,2,2)125plt.plot(epochs_range,loss,label="Training Loss")126plt.plot(epochs_range,val_loss,label="Validation Loss")127plt.legend(loc="upper right")128plt.title("Training and Validation Loss")129plt.savefig(RESULTS)130131132if__name__=="__main__":133train_ds,val_ds,class_names=prepare_data()134history=train_and_save_model(train_ds,val_ds,class_names)135plot_training_results(history)
For macOS Apple Silicon, the above code only works on macOS 12.x Monterey with the latest
tensorflow-macos and tensorflow-metal versions. It will crash on macOS 11.x Big Sur due to
bugs in the outdated tensorflow versions.
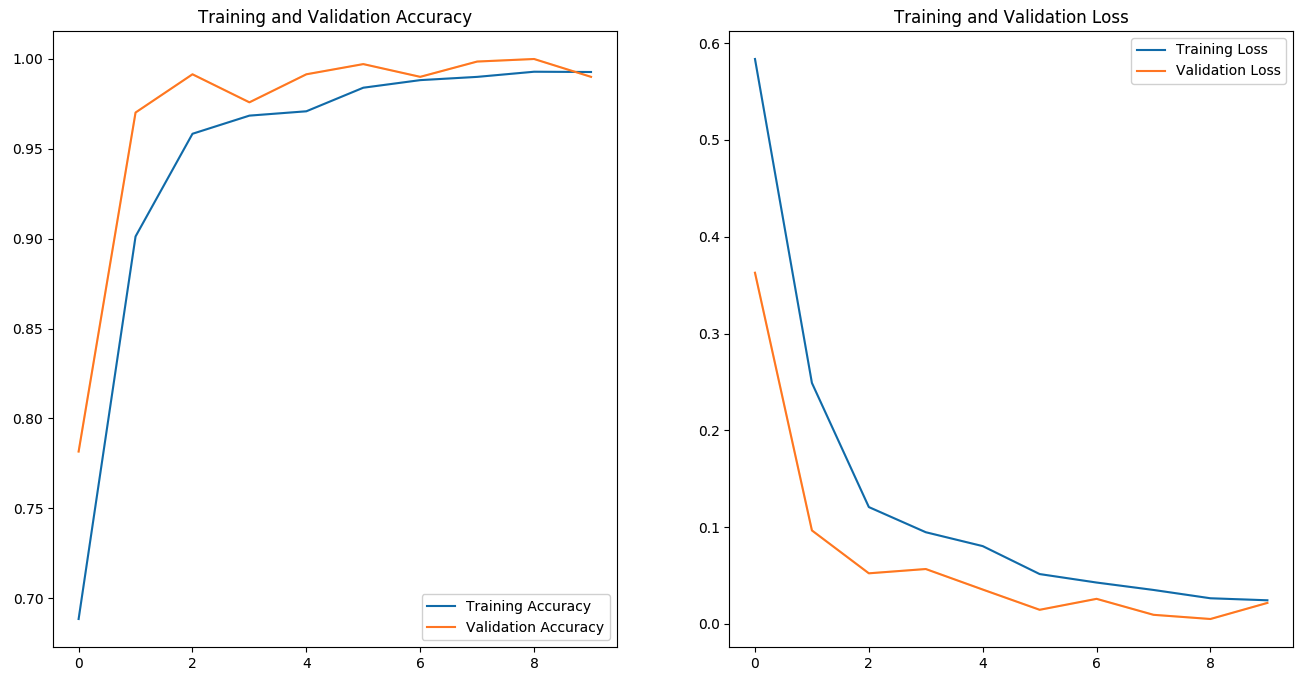
The model will be trained for 10 epochs, and when training is completed, a new weights
folder and training_results.png will be created:
The plots from training_results.png shown below indicate that the model has performed well on
the validation dataset, and we are ready to create a custom model node from it.
This section will show you how to convert your trained model into a custom PeekingDuck node, and
give an example of how you can integrate this node in a PeekingDuck pipeline. It assumes that you
are already familiar with the process of creating custom nodes, covered in the earlier
custom node tutorial.
1""" 2Casting classification model. 3""" 4 5fromtypingimportAny,Dict 6 7importcv2 8importnumpyasnp 9importtensorflowastf1011frompeekingduck.pipeline.nodes.nodeimportAbstractNode1213IMG_HEIGHT=18014IMG_WIDTH=180151617classNode(AbstractNode):18"""Initializes and uses a CNN to predict if an image frame shows a normal19 or defective casting.20 """2122def__init__(self,config:Dict[str,Any]=None,**kwargs:Any)->None:23super().__init__(config,node_path=__name__,**kwargs)24self.model=tf.keras.models.load_model(self.weights_parent_dir)2526defrun(self,inputs:Dict[str,Any])->Dict[str,Any]:27"""Reads the image input and returns the predicted class label and28 confidence score.2930 Args:31 inputs (dict): Dictionary with key "img".3233 Returns:34 outputs (dict): Dictionary with keys "pred_label" and "pred_score".35 """36img=cv2.cvtColor(inputs["img"],cv2.COLOR_BGR2RGB)37img=cv2.resize(img,(IMG_WIDTH,IMG_HEIGHT))38img=np.expand_dims(img,axis=0)39predictions=self.model.predict(img)40score=tf.nn.softmax(predictions[0])4142return{43"pred_label":self.class_label_map[np.argmax(score)],44"pred_score":100.0*np.max(score),45}
The custom node takes in the built-in PeekingDuck img data type, makes a prediction based
on the image, and produces two custom data types: pred_label, the predicted label (“defective”
or “normal”); and pred_score, which is the confidence score of the prediction.
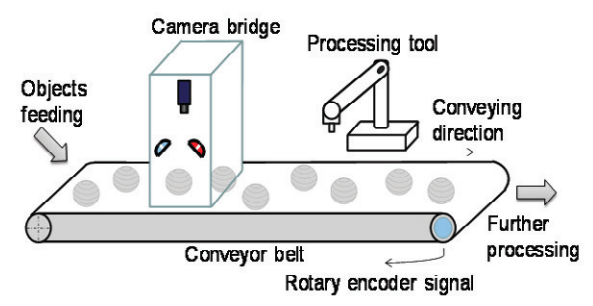
We’ll now pair this custom node with other PeekingDuck nodes to build a complete solution. Imagine
an automated inspection system like the one shown below, where the castings are placed on a
conveyor belt and a camera takes a picture of each casting and sends it to the PeekingDuck pipeline
for prediction. A report showing the predicted result for each casting is produced, and the quality
inspector can use it for further analysis.
Vision Based Inspection of Conveyed Objects (Source: ScienceDirect)
Edit the pipeline_config.yml file to use the input.visual node to read in the images,
and the output.csv_writer node to produce the report. We will test our solution on the 10
casting images in castings_data/inspection, where each image’s filename is a unique casting ID
such as 28_4137.jpeg.
Line 2 input.visual: tells PeekingDuck to load the images from
castings_data/inspection.
Line 4 Calls the custom model node that you have just created.
Line 5 output.csv_writer: produces the report for the quality inspector in a CSV file
castings_predictions_DDMMYY-hh-mm-ss.csv (time stamp appended to file_path).
This node receives the filename data type from input.visual,
the custom data types pred_label and pred_score from the custom model node,
and writes them to the columns of the CSV file.
Run the above with the command peekingduck run.
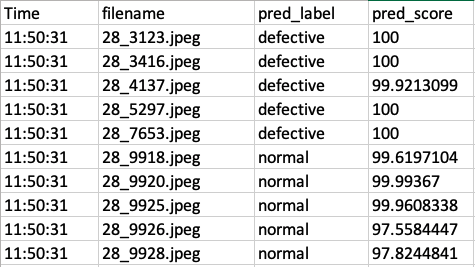
Open the created CSV file and you would see the following
results. Half of the castings have been predicted as defective with high confidence scores. As the
file name of each image is its unique casting ID, the quality inspector would be able to check the
results with the actual castings if needed.
To visualize the predictions alongside the casting images, create an empty Python script named
visualize_results.py, and update it with the following code:
visualize_results.py:
Show/Hide Code for visualize_results.py
1""" 2Script to visualize the prediction results alongside the casting images 3""" 4 5importcsv 6 7importcv2 8importmatplotlib.pyplotasplt 910CSV_FILE="casting_predictions_280422-11-50-30.csv"# change file name accordingly11INSPECTION_IMGS_DIR="castings_data/inspection/"12RESULTS_FILE="inspection_results.png"1314fig,axs=plt.subplots(2,5,figsize=(50,20))1516withopen(CSV_FILE)ascsv_file:17csv_reader=csv.reader(csv_file,delimiter=",")18next(csv_reader,None)19fori,rowinenumerate(csv_reader):20# csv columns follow this order: 'Time', 'filename', 'pred_label', 'pred_score'21image_path=INSPECTION_IMGS_DIR+row[1]22image_orig=cv2.imread(image_path)23image_orig=cv2.cvtColor(image_orig,cv2.COLOR_BGR2RGB)2425row_idx=0ifi<5else126axs[row_idx][i%5].imshow(image_orig)27axs[row_idx][i%5].set_title(row[1]+" - "+row[2],fontsize=35)28axs[row_idx][i%5].axis("off")2930fig.savefig(RESULTS_FILE)
In Line 10, replace the name of CSV_FILE with the name of the CSV file produced on your system,
as a timestamp would have been appended to the file name.
Run the following command to visualize the results.
An inspection_results.png would be created, as shown below. The top row of castings are clearly
defective, as they have rough, uneven edges, while the bottom row of castings look normal.
Therefore, the prediction results are accurate for this batch of inspected castings. The quality
inspector can provide feedback to the manufacturing team to further investigate the defective
castings based on the casting IDs.
The previous example was centered on the task of image classification. Object detection is
another common task in Computer Vision. PeekingDuck offers several pre-trained
object detection model nodes which can detect up to
80 different types of objects, such as persons, cars, and dogs, just to name a few. For the
complete list of detectable objects, refer to the
Object Detection IDs page. Quite often, you may need to train
a custom object detection model on your own dataset, such as defects on a printed circuit board
(PCB) as shown below. This section discusses some important considerations for the object detection
task, supplementing the guided example above.
PeekingDuck’s object detection model nodes conventionally receive the img data type, and
produce the bboxes, bbox_labels, and bbox_scores data types. An example of
this can be seen in the API documentation for a node such as model.efficientdet. We
strongly recommend keeping to these data type conventions for your custom object detection node,
ensuring that they adhere to the described format, e.g. img is in BGR format, and
bboxes is a NumPy array of a certain shape.
This allows you to leverage on PeekingDuck’s ecosystem of existing nodes. For example, by ensuring
that your custom model node receives img in the correct format, you are able to use
PeekingDuck’s input.visual node, which can read from multiple visual sources such as a
folder of images or videos, an online cloud source, or a CCTV/webcam live feed. By ensuring that
your custom model node produces bboxes and bbox_labels in the correct format, you
are able to use PeekingDuck’s draw.bbox node to draw bounding boxes and associated labels
around the detected objects.
By doing so, you would have saved a significant amount of development time, and can focus more on
developing and finetuning your custom object detection model. This was just a simple example, and
you can find out more about PeekingDuck’s nodes from our API Documentation, and
PeekingDuck’s built-in data types from our Glossary.